Backup / Restore databases in Odoo (OpenERP)
There are four main types which are possible when using the PostgreSQL database server.
SQL Dump
An SQL dump of a database consists of a file containing a series of SQL statements which, when executed, will recreate the database, including its data, users, and permissions. As the resulting files are often extremely large, it is not uncommon to store them in a compressed form by either by bzip2 or using the built-in compression functionality of the pg_dump application.
This method is piping them through a utility such as ideal for archiving either a single database from a cluster or all the databases on a cluster in a form which is usable by the greatest possible number of database systems and PostgreSQL versions. It is also ideal if you wish to transfer a subset of the current databases to a different cluster, even one using a different encoding.
File-System Backup
A file-system level backup involves making a copy of all the files used by the database cluster. Whilst, on the surface, this method may look the easiest it has two major drawbacks which make it impractical for normal use. The first is that the database server must be stopped before the backup is taken to ensure consistency of the files.
The second is that it is impossible to restore only a single database. The first of these limitations may be mitigated by using the rsync utility in two phases, the first with the database running and the second with the database stopped, which will greatly reduce the time that the database will be unavailable.
LVM Snapshot
An LVM snapshot is often cited as one of the easiest and most reliable methods of backing up a complete database cluster however in practice this is not always the case. As the snapshot mechanism of LVM is not integrated with the filesystem in any way there is always the danger that the database is in an inconsistent state when the snapshot is made.
Although the database server should usually be able to recover from partially completed transactions by rolling-back said transactions it is by no means guaranteed to succeed on a heavily loaded server which may have had dozens of transactions open at the time of the snapshot. If, on the other hand, it is possible to ensure that no writes are taking place then this is still an excellent backup method. Alternatively, when combined with PITR this method can be employed even on heavily utilized systems.
Point-In-Time-Recovery (PITR)
Point-In-Time-Recovery is the most complex backup strategy we shall discuss here. It utilizes Write-Ahead-Log (WAL) archiving to provide the ability to recover the database state to any point since the last backup.
Also, as the WAL files containing every started are available the backup does not consistent allowing the database cluster clients at all times. It is also possible to a server to read the stream of a transaction since the backup has to be perfectly internally to remain active and serving arranges for another database WAL files and provide a constant hot standby node which will always have a nearly-current copy of the databases.
How to create a backup/restore the database in OpenERP / Odoo?
There are two methods to perform backup and restore operation for Odoo/OpenERP database.
Method 1: Using GUI
Follow the steps to create a backup of database in Odoo and restore a database.
Steps: Get Backup of Database
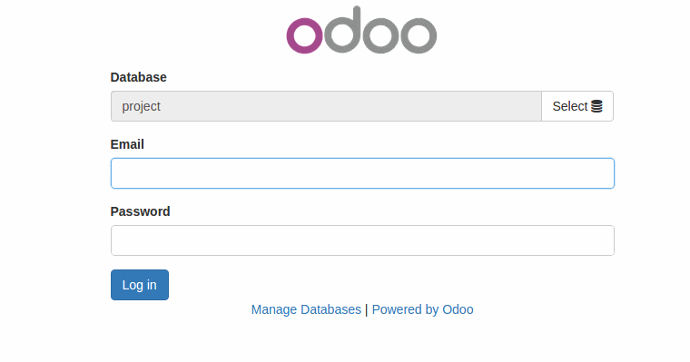
1. Go to Login Page.
2. Click on Manage Databases.
3. There are various options available.
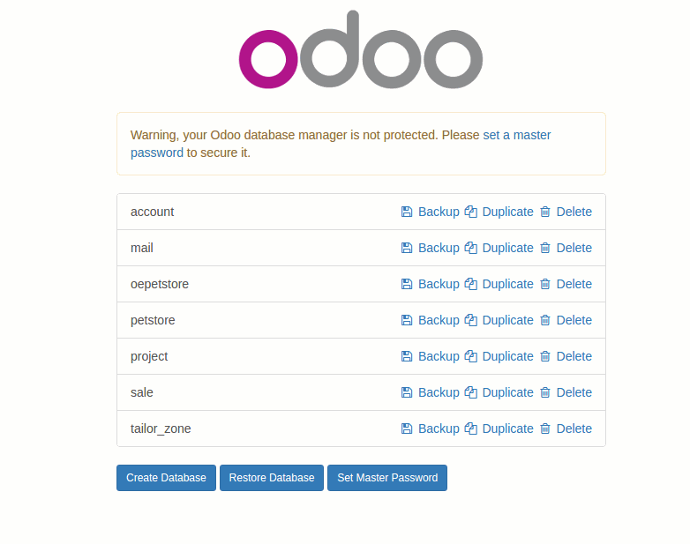
4. You can get backup of a database, restore a database, Create a Duplicate of a database and Delete any database on this page.
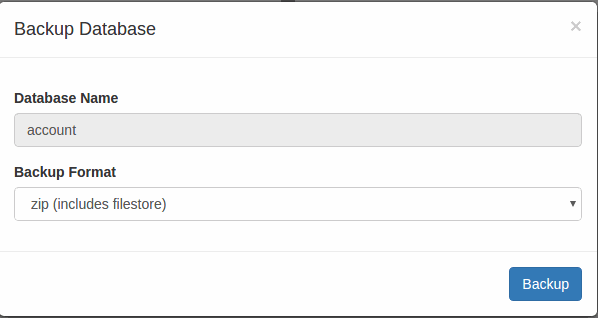
5. Select Database name and Click on the Backup button.
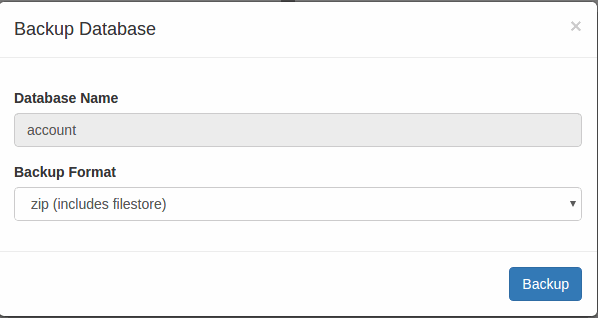
6. Select Backup Format and Click on the Backup button.
Steps: Restore Database Backup
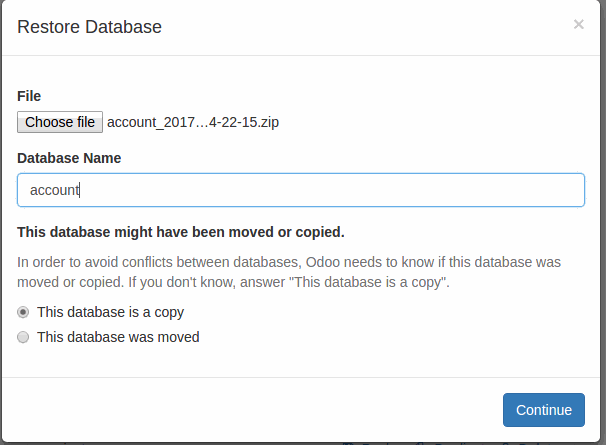
4. Follow steps 1 to 3 of Get Backup and Then Click on Restore Database button.
5. Click on Choose file and Select database file. Write New database name and select moved or copied option.
6. Finally, Click on the continue button and finish the Restore database process.
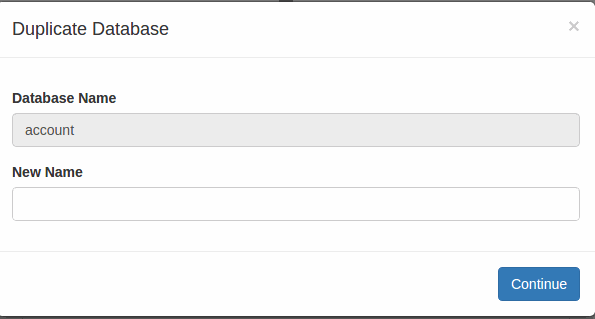
Steps: Duplicate Database
4. Follow steps 1 to 3 of Get Backup and Then Click on the Duplicate button of any database.
5. Write the new name of the database and then click on the Continue button.
Steps: Delete Database
4. Follow steps 1 to 3 of Get Backup and Then Click on Delete button of any database.
5. Click on Delete button.
Method 2: Using Command Line
Follow the steps to create a backup of a database and restore a database.
Creating SQL dump backups:
As we discussed in the previous section, the SQL dump method of database backup provides a simple method to produce a consistent backup of a single database or an entire cluster by generating a plain text file containing a series of SQL statements which, when executed, will recreate the database, including its data, users, and permissions. Creating an SQL dump of a single database The example below shows how the pg_dump application, provided with all PostgreSQL installations, can be used to back up a single database.
Creating an SQL dump of a single database:
The example below shows how the pg_dump application, provided with all PostgreSQL installations, can be used backup a single database.
pgadmin@odoo ~ $ pg_dump dbname > dbname-20110701.sql
If you examine the contents of the backup file we just created you will see a series of SQL statements capable of recreating the database including the table schema, the data, any indexes and sequences which we had created as well as the permissions currently assigned to our database users.
Note: Although the SQL dump file we created above contains all the information required to recreate the database including the table schema, the data, any indexes and sequences which we had created as well as the permissions currently assigned to our database users there are two things this file does not contain, however. The first notable omission is any statements to recreate the actual database. The second is any statements to recreate the database users. The reason for this is that the database and any users are not technically part of the database but a part of the cluster's configuration information. We shall examine creating backups of this information in a later section.
If the database is particularly large you may wish to enable compression of the SQL dump file. As shown in the example below this can be easily achieved by passing the -Z n option, where n is a number between 0 and 9 with the higher number indicating higher compression, to the pg_dump utility
pgadmin@odoo ~ $ pg_dump dbname -Z 9 > dbname-20110701.sql.gz
The note above raises the important point that an SQL dump of a database, made with the default options does not contain any SQL statements to recreate either the database itself or any of its users. If you are intending to restore the database to a cluster which does not already have a database with this name it is often convenient to include such commands when making the dump by passing -C option to the pg_dump utility as shown in the following example.
pgadmin@odoo ~ $ pg_dump dbname -C > dbname-20110701.sql
Note: When creating an SQL dump of a database which includes commands to recreate the database, as shown in the above example. it should be remembered that it is therefore much more difficult to restore such a backup to a database of a different name then a similar backup without such commands.
Creating an SQL dump of a complete database cluster:
All the above examples showed how to back up a single database from a cluster. While this is useful it is often desirable to create a backup of a complete cluster including all databases, tables, data, indexes, and sequences, as well as any users which have been created on the cluster.
As shown in the example below the pg_dumpall application can be used to accomplish this in exactly the same way as when backing up a single database using the pg_dump application.
pgadmin@odoo ~ $ pg_dumpall > db-backup-20110701.sql
Current versions of the pg_dumpall do not support making compressed backups. If you wish to back up a large cluster then the output of pg_dumpall can be piped through the bzip2 utility before being redirected to a file as shown in the following example.
pgadmin@odoo ~ $ pg_dumpall | bzip2 > db-backup-20110701.sql
When creating a backup of an entire database cluster with very large tables it is often useful to break the backup into pieces of a more manageable size. The example below creates a compressed backup of a complete database cluster. using the split utility to break the resulting output into files suitable for long-term archival on 700MB Compact Disks.
pgadmin@odoo ~ $ pg_dumpall | bzip2 | split -b 690m -d - split-bz2-db-backup-20110701.sql
Restoring SQL dump backups:
Now that we have explored how to create SQL dump backup files of single databases and complete database clusters we shall examine how to restore such backups to recreate a fully functioning database or cluster.
Restoring an SQL dump of a single database:
As SQL dump backup files are simply a collection of SQL statements they can be easily replayed using the psql client application provided with PostgreSQL. Assuming that the -C option was not provided then the database will have to be created first using the createdb command. The example below As shows the sequence of commands required to restore such a backup.
pgadmin@odoo ~ $ createdb dbname
pgadmin@odoo ~ $ psql dbname < dbname-20110701.sql
Note: In all of the examples included in this section the database users or roles referenced by the SQL dump file must already exist before the database can be recreated. if the backup is being restored to a new cluster then these roles will either need to be manually recreated or restored from a meta-data backup as described in the section with that name below.
If the -Z option was passed to the pg_dump application when creating the backup file then the zcat utility will have to be used to uncompress the backup file before piping it to the psql application. An example of using the zcat utility in conjunction with the psql application is provided below.
pgadmin@odoo ~ $ createdb dbname
pgadmin@odoo ~ $ zcatdbname-20110701.sql.gz | psqldbname
Finally, if the -C option was passed to the pg_dump application when creating the backup file then there is no need to create the database using create db first as the backup file contains the appropriate SQL statements required to recreate it. As you can see from the example below a database name is still required by the plsql application so we have used the internal database named postgres as it is certain to appear on all installations.
pgadmin@odoo ~ $ psql postgres < dbname-20110701.sql
Restoring a backup of a complete database cluster:
Restoring an SQL dump of a complete database cluster from an SQL dump file is accomplished in exactly the same way as restoring a single database from a -C option specified. As the backup file already contains the commands required to recreate databases and roles there is no backup created with the need to manually recreate these first.
pgadmin@odoo ~ $ psql postgres < db-backup-20110701.sql
if a bzip2 compressed backup was created then the bzcat application can be used to uncompress the backup file before piping it to the psql application. As you can see in the example below we use the Postgres internal database as the initial database as this is guaranteed to exist on all installations.
pgadmin@odoo ~ $ bzcat db-backup-20110701.sql.bz2 | psql postgres
The final example in this section shows how to restore a bzip2 compressed backup of an entire database cluster that was previously broken into pieces using the split utility.
pgadmin@odoo ~ $ bzcat split-bz2-db-backup-20110701* | psql postgres
Backing up and restoring metadata:
We mentioned in the previous section that user or role data was stored separately from the databases referenced by those roles and therefore it is not included in an SQL dump backup file generated by the pg_dump application. Generally, when creating a backup of a single database, that backup is expected to be restored to the same cluster. If this is the case then the absence of user metadata in the backup file is not a problem as the roles will already exist. If, however, the backup is restored to a different database role referenced by that backup will not already exist. For this reason, it is often useful to be able to make a backup of only the user cluster then the metadata.
pgadmin@lisa ~ $ pg_dumpall -r > db-roles-20110701.sql
These roles can then be recreated by replaying the SQL statements from the backup file in the same way as any other SQL dump file as shown below. Alternatively, the relevant commands can be extracted from the resulting file and replayed manually or added to another backup file to ensure that our roles also recreated.
pgadmin@lisa ~ $ psqlpostgres < db-roles-20110701.sql
Note: Care should be taken with any backup files containing user metadata. Passwords are stored encrypted with the MD5 message digest algorithm which is known to be relatively insecure. It should also be noted that replaying a user metadata SQL dump file will reset the passwords for all listed roles to that at the time the backup of the database was created.